在spring boot中三分钟上手日志堆积系统kafka
kafka消息堆积能力比较强,可以堆积上亿的消息,特别适合日志处理这种实时性要求不太高的场景,同时支持集群部署,相比redis堆积能力和可靠性更高
完整项目代码已上传github:https://github.com/neatlife/mykafka
可以通过下面的步骤快速上手这个kafka
获取一个可用的kafka实例
可以使用docker一键启动一个kafka集群,参考:https://github.com/simplesteph/kafka-stack-docker-compose
git clone https://github.com/simplesteph/kafka-stack-docker-compose.git
cd kafka-stack-docker-compose
docker-compose -f full-stack.yml up -d
操作效果如下
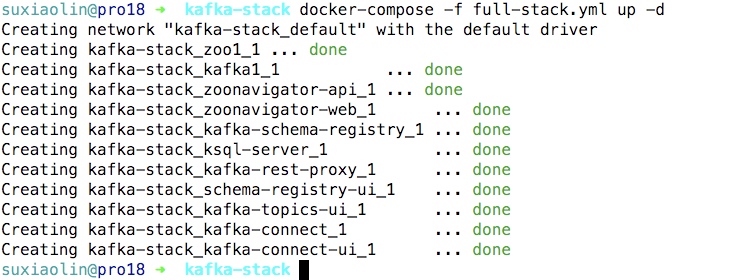
使用命令docker-compose -f full-stack.yml ps获取可以kafka监听的端口
阿里云ons队列监控api深度使用
文档地址:
- https://help.aliyun.com/document_detail/29597.html
- https://help.aliyun.com/document_detail/44419.html
拿获取 查询消费堆积 这个关键监控接口举例
创建项目并引入监控包和客户端包
创建spring boot项目
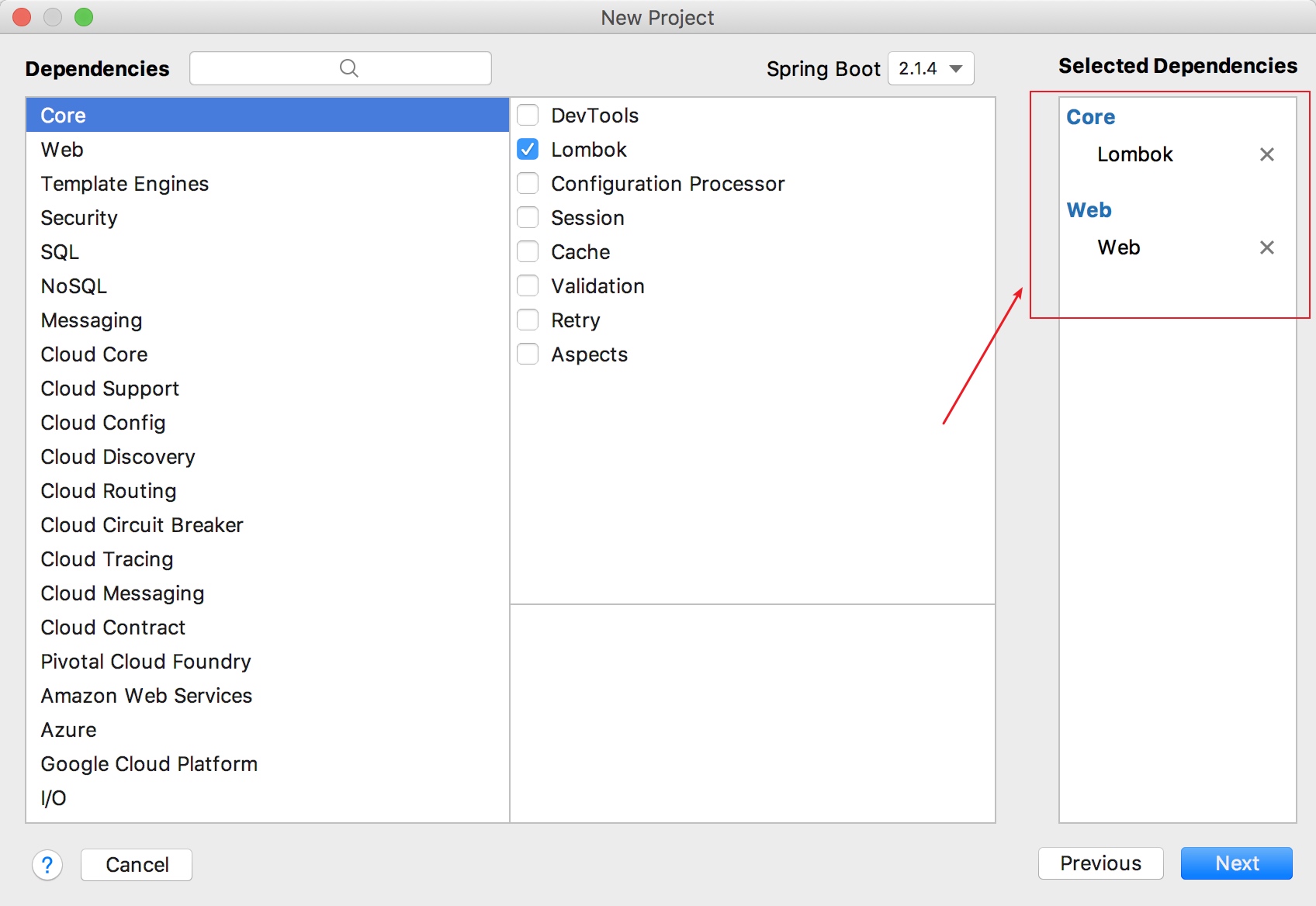
引入lombok和web包
阿里云ons消息队列使用小记
java反序列化阿里云上的消息文件
String serializeFile = "/Users/suxiaolin/filerun/user-files/superuser/0A2A003B0ADA439F5B3D171876FA0042";
File file = new File(serializeFile);
byte bt[] = new byte[(int)file.length()];
FileInputStream fis = new FileInputStream(file);
fis.read(bt);
fis.close();
MessageEvent messageEvent = (MessageEvent) SerializationUtils.deserialize(bt);
System.out.println(JsonUtils.obj2json(messageEvent.getDomain()));
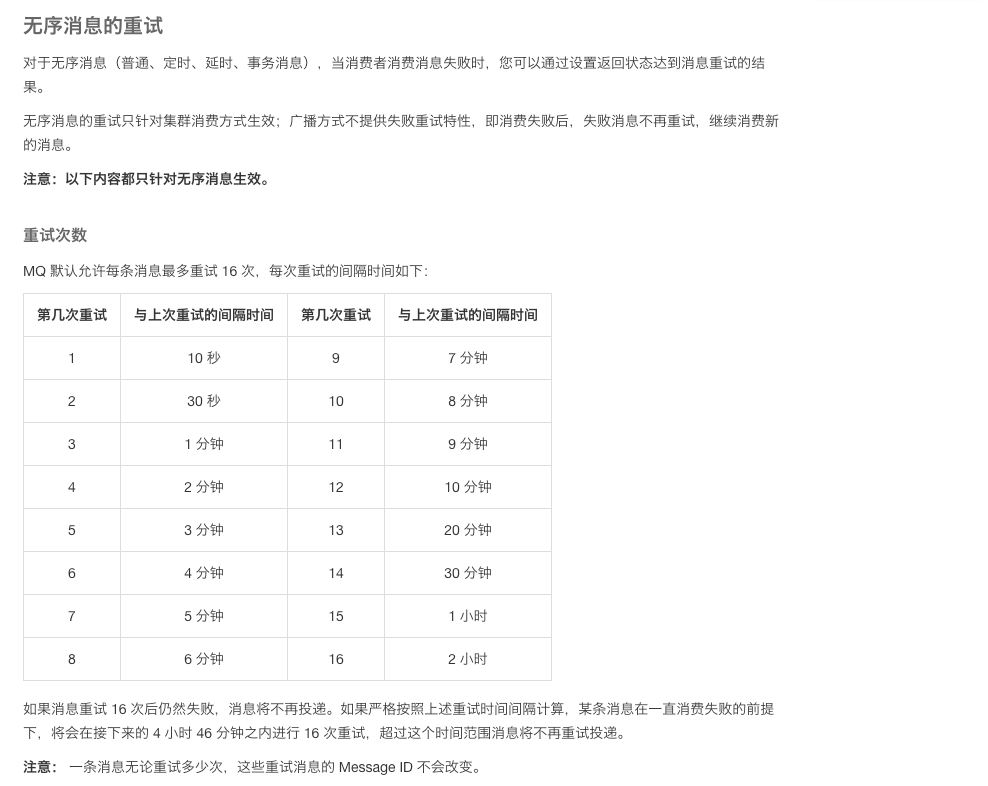
默认的消息重试次数
https://help.aliyun.com/document_detail/43490.html
Copyright © 2015 Theme used GitHub CSS. 访问人/ 次