参与了论坛系统的开发,总结一下
技术栈
- 使用git进行代码版本控制
- 使用jumpserver管理服务器资产权限
- 使用kafka做消息队列系统
- 使用elasticsearch存放大批量关联数据
- 使用内部研发的代码部署审核系统
- 使用yii1框架(历史遗留系统了)
- 使用qconf做分布式配置中心
- 使用logrotate做日志轮转
- 使用sphinx做文本分词和搜索
- 使用confluence做文档管理
- 使用禅道做项目bug管理
内容主表设计
内容系统内容表主体主要是存放内容公有的字段,比如帖子标题、帖子类型、浏览数等
一些特殊的字段,比如帖子内容字段因为占用空间比较大(通常是text数据类型),并不适合放在内容主体表中(影响查询速度),可以单独创建一张表来进行存储
CREATE TABLE `tb_subject` (
`subject_id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(255) NOT NULL DEFAULT '',
`subject_type` text NOT NULL DEFAULT 0,
`uid` bigint(20) unsigned NOT NULL DEFAULT 0,
`view_cnt` int(11) NOT NULL DEFAULT 0,
`display_yn` tinyint(1) NOT NULL DEFAULT 1,
`create_date` datetime NOT NULL DEFAULT current_timestamp() COMMENT '创建时间',
`update_date` datetime NOT NULL DEFAULT current_timestamp() ON UPDATE current_timestamp() COMMENT '更新时间',
PRIMARY KEY (`subject_id`),
KEY `idx_uid` (`uid`,`create_date`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='贴子主体表';
帖子内容文本类型的字段通常设计一张新表来单独存储
CREATE TABLE `tb_subject_content` (
`subject_id` int(11) unsigned NOT NULL DEFAULT 0,
`content` text DEFAULT NULL COMMENT '帖子内容',
PRIMARY KEY (`post_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='贴子内容';
扩展属性表设计
对非标准的内容数据进行结构化存储,比如帖子的标签、关键词等(只有部分帖子有,并且数量不固定)
CREATE TABLE `tb_column_info` (
`column_id` int(11) unsigned NOT NULL DEFAULT 0,
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`extend_type` mediumint(6) NOT NULL DEFAULT 0,
`extend_id` int(11) unsigned NOT NULL DEFAULT 0,
`extend_status` tinyint(1) NOT NULL DEFAULT 0,
`extend_content` varchar(500) NOT NULL DEFAULT '',
`create_time` datetime NOT NULL DEFAULT current_timestamp(),
PRIMARY KEY (`column_id`,`id`),
KEY `idx_id` (`id`),
KEY `idx_column_id` (`extend_id`,`extend_type`,`extend_status`,`column_id`),
KEY `idx_type_time` (`extend_type`,`extend_status`,`create_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='属性扩展表';
分类/标签 表设计
分类表有两种设计方案,一种是专为帖子主体表设计一个分类表,和帖子id进行强关联,另一种是设计一张通用的分类表,可以和帖子以外的内容进行关联,比如新闻内容,一般采用通用的分类表设计,这样可以最大限度的减少重复的分类表的维护,分类表设计参考如下:
CREATE TABLE `tb_tag` (
`tag_id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`tag_name` varchar(255) NOT NULL DEFAULT '',
`tag_type` tinyint(3) NOT NULL DEFAULT 0,
PRIMARY KEY (`tag_id`),
KEY `idx_tag_name` (`tag_name`),
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='标签表';
统计数据处理
涉及到内容的系统通常都会有大量的统计数据,比如评论数、浏览数等
冗余字段设计
评论数: 帖子下用户发表评论时,在帖子主体表中的评论计数器+1
浏览数: 用户在浏览帖子详情时,帖子主体表冗余的浏览数+1
数据更新机制
- 接口实时更新
- 使用消息队列进行更新
@他人设计
<at_user uid="123456">用户昵称</at_user>
大数据技术
在以上的数据更新机制中,存在的问题是如果访问量大,冗余字段的更新会非常频繁,这时可以采用大数据技术比如 Spark Streaming来进行聚合数据、批量更新
前期内容来源
可以通过抓取,适配到内容数据表中
- 知乎
- 网易
- 今日头条
三方服务
- 视频存储服务:七牛 参考:https://www.qiniu.com/products/kodo
分表技巧
目前有很多的hash算法,使用上还是推荐使用取模的算法,这样使用时根据分表id的末尾数字就可以确定数据在那个分表里了,提高核对数据时找表的效率
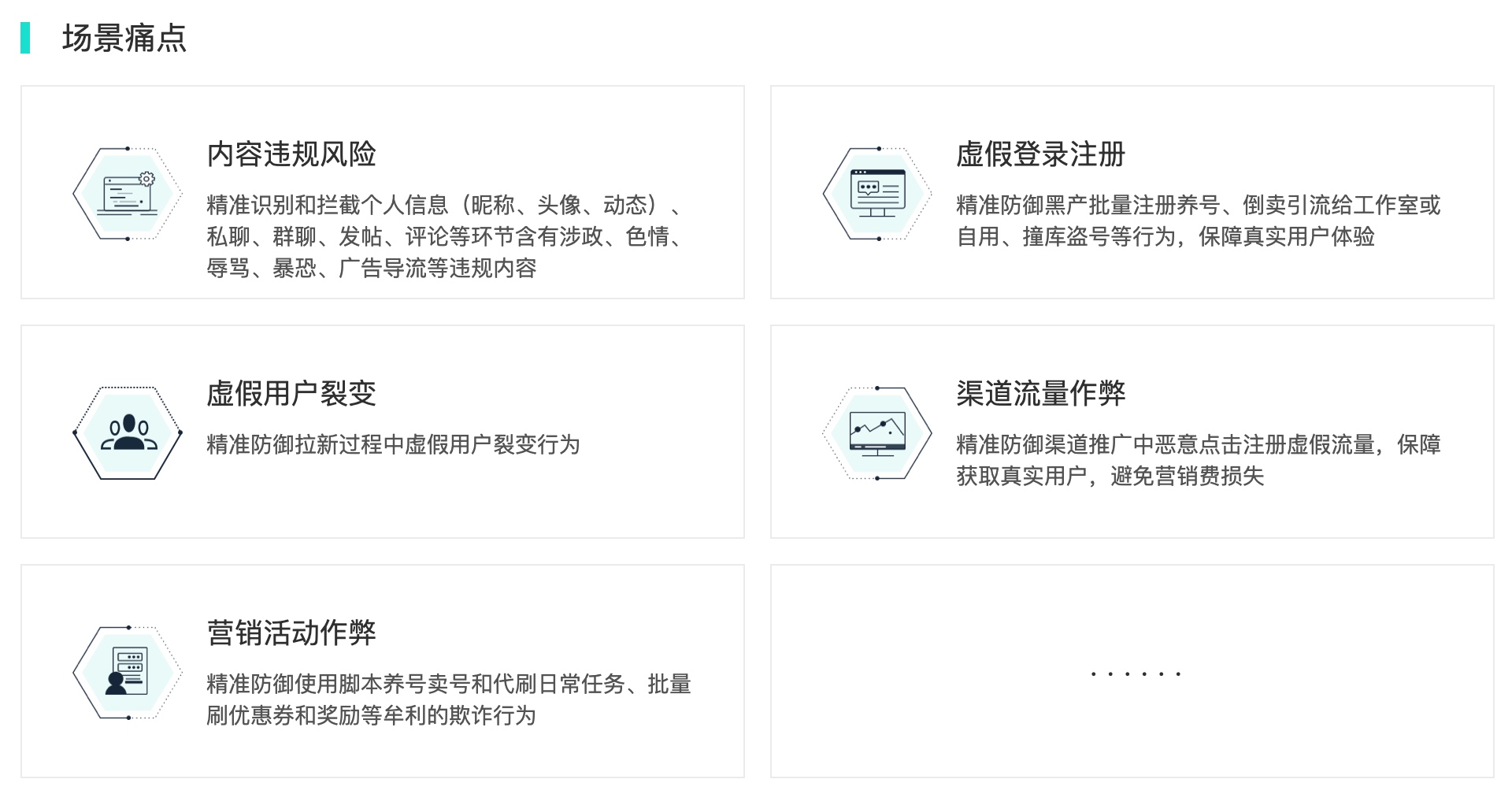
内容审核
机审
敏感词过滤可以使用易盾,参考:https://dun.163.com/
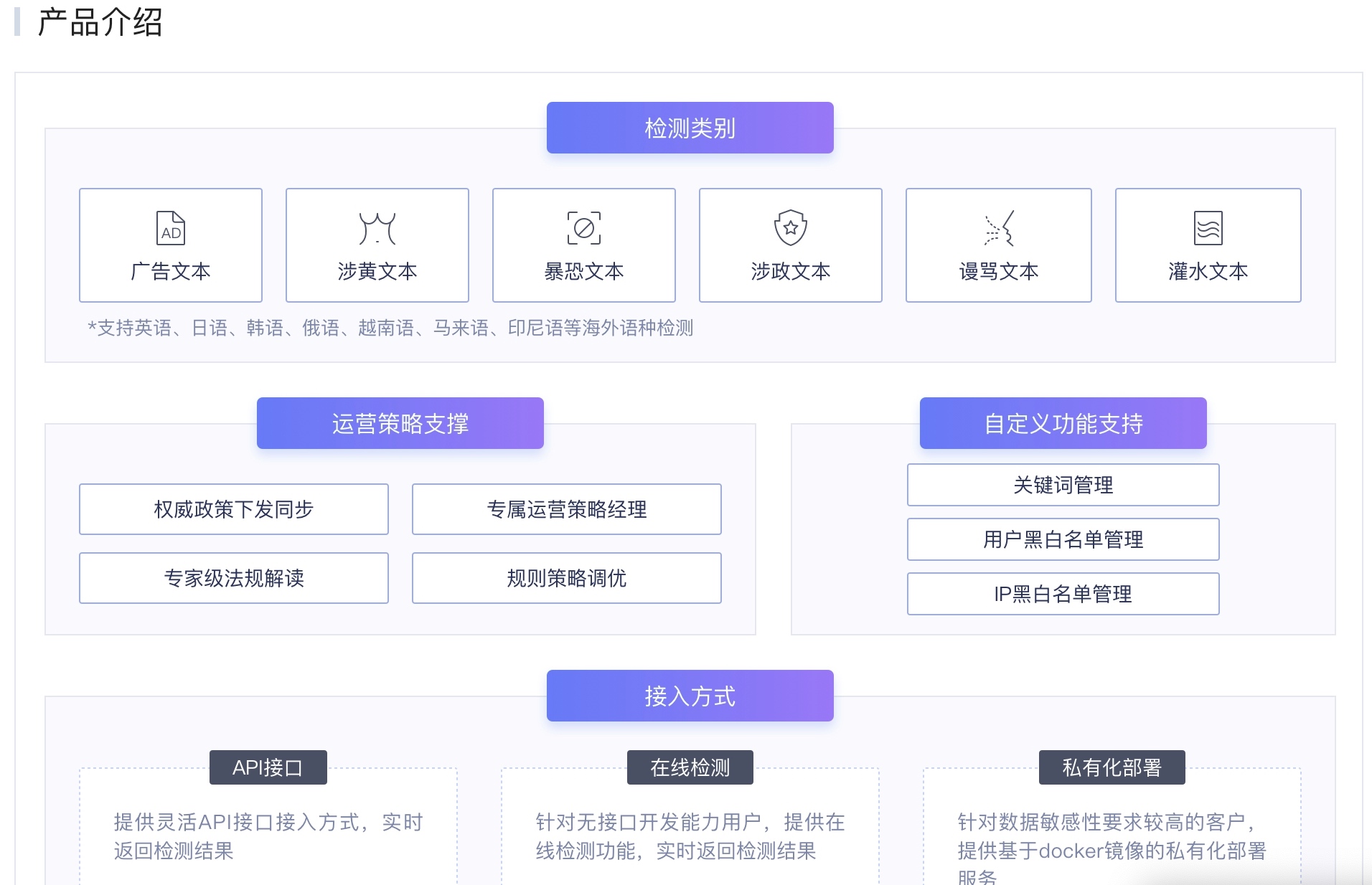
作弊数据可以使用数美,参考:https://www.ishumei.com/solution/social.html?keyUrl=https%3A%2F%2Fwww.ishumei.com%2F&keyRefererHost=www.google.com
人审
开发审核后台由审核专员审核内容
商业模型
这个内容是公司业务的流量入口,承担着留住老用户,招揽新用户的任务
流量入口:
- 微博
- 公众号
- 朋友圈
一些注意的点
内容的评论、回复可以单独建表存,没有必要共用一张表
参考资料
- https://blog.csdn.net/xjk201/article/details/80894017
- https://www.geek-share.com/detail/2605073300.html
持续更新中...